

저번 글에서는 변수를 다루는 기본 코드와 기본적인 자료형에 대해 알아보았습니다. 이번 시간에는 자료형에 어떤 종류가 있는지 보고 또 어떻게 작동하는 지 보도록 하겠습니다.
∨ 자료형
저번 글에서 설명드렸으니 간략히 설명드리자면 데이터의 종류를 자료형이라고 합니다. 자료형(데이터의 종류)에는 크게 3가지가 있습니다.
- 정수
- 부동 소수점(실수)
- 문자
그러면 순서대로 보도록 하겠습니다.
∨ 정수의 크기, sizeof 연산자
정수는 -3, 10, 0 등의 실수 없는 수치 데이터를 의미합니다. 정수 자료형은 크기와 음수 존재 여부에 따라 다시 한번 다양한 자료형으로 나뉩니다. 우선 크기에 따라 정수의 자료형이 어떤 것이 있는 지 보도록 하겠습니다.
| 정수 자료형 | ||
| 크기 | 자료형 | 값의 범위 |
| 1byte | char | -128 ~ +128 |
| 2byte | short | -32768 ~ +32767 |
| 4byte | int, long | -2147483648 ~ +2147483647 |
| 8byte | long, long long | -9223372036854775808 ~ + 9223372036854775807 |
여기서 long 자료형이 2개 있는 이유는 시스템 환경(window, macOS 등)에 따라 크기가 4byte이거나 8byte이기 때문입니다. 윈도우에서는 long 자료형의 크기는 4btye입니다.
이 자료형들의 크기를 알고, 자료형 간의 순서를 전체적으로 파악하기 힘들 수 있습니다. 근데 이 두 가지를 아시면 매우 편리할 겁니다. 첫 번째는 바로 int를 기준점으로 삼는 것인데요. 그 이유는 char형을 제외한 대부분의 정수 자료형은 int 형을 확장한 표현이기 때문입니다. 예를 들면 short는 사실 short int의 줄임 표현이고, long과 long long은 각각 long int, long long int의 줄임 표현이기 때문입니다.
#include <stdio.h>
int main(void) {
short int x1;
int x2;
long int x3;
long long int x4;
return 0;
}
따라서 int형이 4byte임을 기억하고, short형은 short int의 줄임 표현으로 int형 크기의 절반, long long형은 long long int의 줄임 표현으로 int형 크기의 2배로 기억하면 좋습니다.
두 번째 방법은 코드로 자료형의 크기를 구하는 것인데요. 자료형의 크기는 sizeof 연산자를 이용하여 자료형의 크기를 구할 수 있습니다. sizeof()에서 괄호 안에 변수, 혹은 데이터, 자료형을 넣어주면 해당 자료형의 크기를 알 수 있습니다. 즉, sizeof(int)나 sizeof(8), sizeof(변수)의 형태로 사용할 수 있습니다. 아래 코드는 변수의 크기를 sizeof 연산자를 이용하여 출력하는 코드입니다.
#include <stdio.h>
int main(void) {
short int x1;
int x2;
long int x3;
long long int x4;
printf("x1 : %d\n", sizeof(x1)); // \n은 줄바꿈 문자
printf("x2 : %d\n", sizeof(x2));
printf("x3 : %d\n", sizeof(x3));
printf("x4 : %d\n", sizeof(x4));
return 0;
}
이 코드의 결과는 아래와 같이 나옵니다.
x1 : 2
x2 : 4
x3 : 4
x4 : 8
좀있다가 int가 기본형식이라는 것을 설명하자.
∨ 정수의 음수 저장 여부
정수 자료형은 음수를 저장할 수 있느냐 아니냐로 나뉠 수 있습니다. int형은 음수를 저장할 수 있습니다.
#include <stdio.h>
int main(void) {
int number = -100;
printf("%d", number); // -100이 출력됨.
return 0;
}
하지만 기존 정수 자료형 앞에 unsigned를 붙여주면 음수를 저장하지 않고 대신 저장할 수 있는 양수의 범위를 넓힙니다.
unsigned 자료형은 다음과 같습니다.
| 정수 자료형 | ||||
| 크기 | 자료형 | 값의 범위 | unsigned 자료형 | 값의 범위 |
| 1byte | char | -128 ~ +128 | unsigned char | 0 ~ +255 |
| 2byte | short | -32768 ~ +32767 | unsigned short | 0 ~ +65535 |
| 4byte | int, long | -2147483648 ~ +2147483647 | unsigned int, unsigned long | 0 ~ +4294967295 |
| 8byte | long, long long | -9223372036854775808 ~ +9223372036854775807 | unsigned long long | 0 ~ +18446744073709551615 |
즉, unsigned를 붙여주면 기존 자료형과 크기(byte)는 동일하나 저장할 수 있는 양수의 범위가 커지게 됩니다. 대신 음수를 저장할 수 없게 되죠. 음수를 저장할 수 있는 범위를 포기하고 그만큼 양수의 범위를 넓히는 것이니깐요.
unsigned 자료형은 다양한 상황에서 유용하게 사용됩니다. 예를 들어 개수나 크기를 저장하는 변수는 음수를 가질 일이 없기 때문에 unsigned 자료형을 사용하는 것이 적절합니다. 특히 대표적인 예가 RGB 값입니다. RGB는 색상을 표현하는 방식으로, 빨강(Red), 초록(Green), 파랑(Blue)의 세 가지 값을 조합하여 색을 나타냅니다. 이때 각 값은 0부터 255 사이의 정수로 표현되며, 음수가 될 수 없습니다. 따라서 RGB 값을 저장할 때는 unsigned char와 같은 자료형을 사용하는 것이 적합합니다.
참고로 unsigned int를 줄여 unsigned라고도 합니다.
#include <stdio.h>
int main(void) {
unsigned x; // unsigned는 unsigned int와 동일한 자료형!
return 0;
}
한 가지 중요한 점은 unsigned는 정수 자료형에만 적용되는 특성이라는 것입니다. 실수 자료형(float, double)에는 unsigned가 존재하지 않습니다. 이는 실수 자체가 양수와 음수를 모두 표현하도록 설계된 자료형이기 때문입니다. 또한 unsigned 변수에 음수를 저장하려는 시도는 가능하지만, 의도하지 않은 결과를 초래할 수 있습니다. 이는 음수를 표현할 수 없기 때문에 내부적으로 값이 변환되어 전혀 다른 값으로 저장되기 때문입니다. 의도치 않는 결과가 무엇인지 궁금하시다면 아래의 코드를 실행해보시길 바랍니다. unsigned 자료형을 출력할 때는 %u를 사용합니다. 이를 참고하여 아래의 코드를 실행해보겠습니다.
#include <stdio.h>
int main(void) {
unsigned int number = -1;
printf("%u", number); // -1이 출력될까?
return 0;
}
아래와 같은 결과가 출력됩니다.
4294967295
이는 %u가 값을 바꿔서 출력하기 때문이 아니라, unsigned 변수에 -1을 저장하는 순간 값이 이미 변환되었기 때문입니다. unsigned 자료형은 음수를 표현할 수 없기 때문에, 내부적으로 매우 큰 양수 값으로 변환되어 저장됩니다.
참고로 %d, %f 등의 문자를 형식 지정자라고 하는데, 형식 지정자는 전달받은 문자를 주어진 형태의 값으로 치환합니다. 정확한 작동 방식은 다다음 글에서 설명드리겠습니다.
기존의 int, long, short 등의 자료형은 음수와 양수를 모두 표현할 수 있다고 하여 signed int, signed long, signed short 자료형이라고 표현할 수도 있습니다. sign이 부호라는 의미도 있기 때문이죠.
#include <stdio.h>
int main(void) {
signed int x; // 잘 쓰이지는 않음.
return 0;
}
하지만 잘 쓰이는 표현은 아니므로 외울 필요는 없습니다.
∨ 2진수
정수는 어떻게 비트로 표현되는지 보도록 하겠습니다. 그전에 알아야 하는 개념이 있습니다. 모든 데이터는 0과 1, 즉 비트로 표현된다는 점과, "진법"입니다.
진법이란 수를 표현하는 방식으로, 어떤 숫자를 기준으로 수를 표현하는지를 의미합니다. 우리가 일상적으로 사용하는 숫자는 10진수이며, 0부터 9까지의 10개의 표기를 사용합니다. 우리는 일상적으로 10진수를 사용하는 예시는 다음과 같습니다. 예를 들어 사과가 하나도 없으면 0, 하나 있으면 1이라고 표현합니다. 이처럼 0부터 9까지의 숫자를 이용하여 사과의 개수를 표현할 수 있습니다. 그렇다면 사과의 개수가 10개보다 많아지면 어떻게 표현할까요? 사용할 수 있는 숫자는 여전히 0부터 9까지뿐입니다. 정답은 더 많은 자리수를 사용하면 됩니다. 15개, 38개, 203개처럼 기존의 방식으로 10개의 표기(0부터 9)로 숫자를 표현하되, 자리수를 여러개 두어 (1의 자리, 10의 자리, 100의 자리) 각 자리수의 숫자를 10진수(0부터 9)로 표현하는 것입니다. 이때, 10진법으로 표현한 숫자를 10진수라고 합니다.
그렇다면 2진법은 어떨까요? 2진법은 2개의 숫자로 수를 표현합니다. 여기서 2개의 숫자란 0과 1이죠. 10진수와 마찬가지로 2 이상의 더 큰 수는 더 많은 자리수를 두어 표현하면 됩니다. 즉 아래와 같이 표현이 가능합니다.
| 10진수 | 2진수 |
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
두 개의 숫자(0, 1)로 표현하되, 더 큰 수는 자리수를 늘려 표현합니다. 이때 2진수의 각 자리에는 0 또는 1이 들어갈 수 있습니다. 이러한 각각의 자리를 비트(bit)라고 합니다. 비트는 컴퓨터에서 데이터를 표현하는 가장 작은 단위입니다. 예를 들어 한 자리는 1비트(1bit), 두 자리는 2비트(2bit)라고 합니다. 즉, 비트 수는 자리수의 개수를 의미합니다.
예를 들어 3비트로 표현할 수 있는 값은 다음과 같습니다.
| 10진수 | 2진수 |
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
즉 3비트로 8개의 정보를 표현할 수 있습니다. 이처럼 n개의 비트로는 2n개의 서로 다른 정보를 표현할 수 있습니다.
이때 어떤 숫자가 2진수인지 10진수인지 표기하는 방법은 아래첨자로 진법을 명시해주는 것입니다. 예를 들어 10이라는 숫자가 있을 때, 이 숫자가 2진수인지 10진수인지 알 수 없습니다. 이를 명시하기 위해서 10이 2진법으로 표현된 수라면 10(10) 이라고 표기하고, 10진법으로 표현된 수라면 10(10) 이라고 표현합니다.
여기서 바이트(byte)라는 단위도 있습니다. 바이트는 8비트를 의미하며, 1byte = 8bit입니다. 그런데 이 byte라는 표현, 어디선가 본 적이 있지 않나요? 바로 자료형의 크기를 나타낼 때였습니다.
| 정수 자료형 | ||||
| 크기 | 자료형 | 값의 범위 | unsigned 자료형 | 값의 범위 |
| 1byte | char | -128 ~ +128 | unsigned char | 0 ~ +255 |
| 2byte | short | -32768 ~ +32767 | unsigned short | 0 ~ +65535 |
| 4byte | int, long | -2147483648 ~ +2147483647 | unsigned int, unsigned long | 0 ~ +4294967295 |
| 8byte | long, long long | -9223372036854775808 ~ +9223372036854775807 | unsigned long long | 0 ~ +18446744073709551615 |
예를 들어 char 자료형의 크기가 1byte라는 것은, 8bit를 사용하여 데이터를 표현한다는 의미입니다. n개의 비트로는 2n개의 서로 다른 정보를 표현할 수 있으므로 8bit로는 28개의 서로 다른 정보를 표현할 수 있습니다. 이때, 28는 256이므로 char형은 256개의 정보를 저장할 수 있습니다. 즉, char형 데이터의 범위는 -128 ~ +127까지이며, 이는 총 256개의 값을 표현할 수 있음을 의미합니다. 따라서 char형 변수는 8비트를 이용하여 -128부터 127 범위의 값을 저장할 수 있습니다.
∨ 2진수와 10진수 간의 변환
이런 내용은 알아두면 이후 내용을 아는데 매우 유용하므로 숙지하는 것이 좋습니다. 이 부분에서는 2진수를 10진수로, 10진수를 2진수로 변환하는 방법에 대해 알아보겠습니다.
우선 10진수를 2진수로 변환하는 방법은 간단합니다. 10진수를 2진수로 반복하여 나누어 생기는 나머지를 이용하는 것입니다. 이를 반복 2분법이라고 하는데, 글을 보는 것보다 어떻게 작동하는 지 우선 보도록 합시다. 10진수 13을 2진수로 변환하는 과정입니다.

13을 2로 반복해서 나누어 몫 6, 나머지 1로 쪼갭니다. 몫 6을 2로 또 나누어 다시 한 번 몫 3, 나머지 0으로 쪼갭니다. 몫 3을 2로 나누어 몫 1, 나머지 1로 쪼갭니다. 몫이 1이 되면 이 과정을 멈추고, 마지막 몫과, 그동안의 나머지를 거꾸로 이어서 1101이라는 숫자를 만듭니다. 이 숫자가 숫자 13을 2진수로 표현한 값입니다.
다음으론 2진수를 10진수로 표현하는 방법입니다. 이번에는 아까 예로 들었던 13의 2진수 값인 1101을 10진수로 변환해보겠습니다. 2진수를 10진수로 변환하는 방법은 간단합니다. 1의 자리수와 1를 곱하고, 2의 자리수와 2를 곱하고, 3의 자리수와 4를 곱하고, 4의 자리수는 8를 곱한 후 다 더하면 됩니다. 즉 자리수가 한 자리 올라갈 때마다 2의 거듭제곱을 곱하고 더하면 됩니다. 이 경우도 글보다는 아래 그림으로 이해를 돕겠습니다.

1101(2) 숫자에 1의 자리부터 2의 거듭제곱수인 1, 2, 4, 8을 곱해주면 됩니다. 만약 자리수가 4개보다 더 많았다면 2의 거듭제곱수를 이어서 16, 32, 64, ...를 각각 곱한 후 다 더해주면 됩니다. 일단 이 예에선 1101 숫자가 4자리수이므로 1, 2, 4, 8을 곱하고 더합니다. 그러면 10진수 13을 알아낼 수 있습니다.
왜 이런 것인지는 이유는 간단합니다만 이 이유를 다룬 글은 아래 링크를 눌러보시면 더 자세히 알 수 있습니다!
<수정>
∨ 정수의 내부 구조
정수는 내부적으로 어떻게 값이 표현되는 지 알아보겠습니다. 정수 자료형 중에서 가장 크기가 작은 char형을 가지고 설명하겠습니다. char형은 크기가 1byte이고, 1byte는 8bit이므로 8자리 2진수로 정수를 나타냅니다. char형은 아래와 같이 표현됩니다.
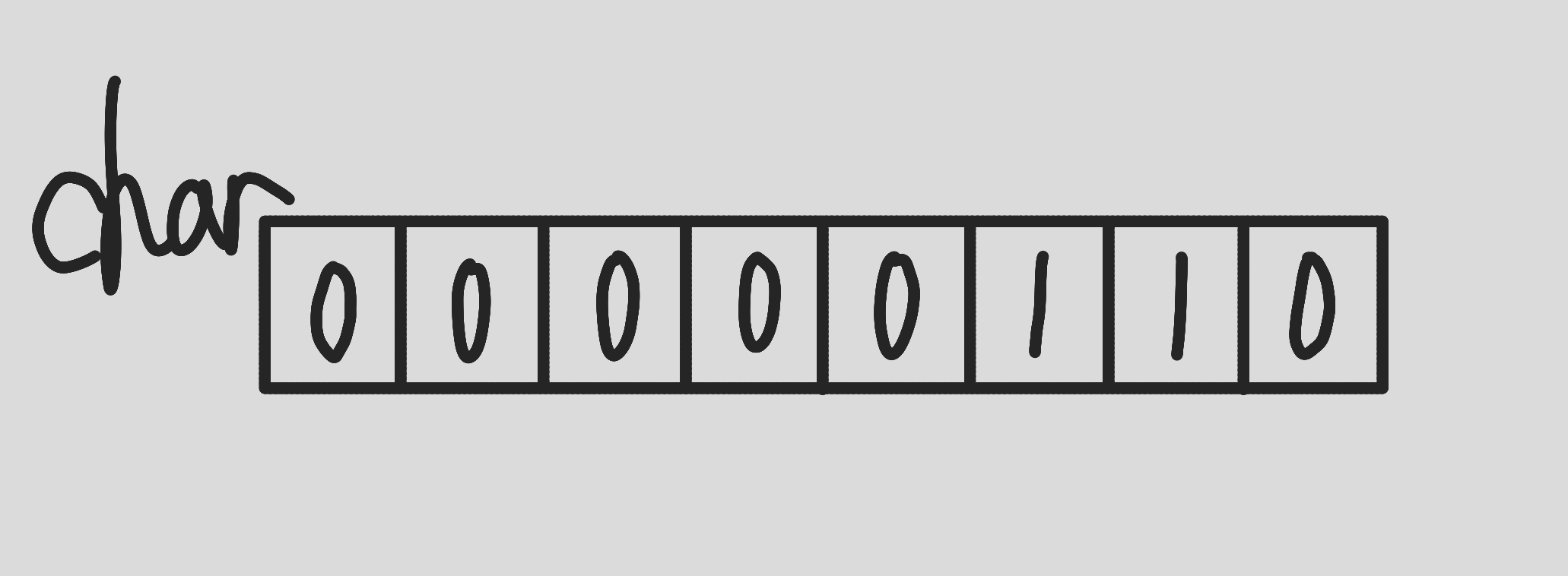
지금 이 char형 데이터는 어떤 데이터를 표현하는 것일까요? 정답은 6(10)입니다. 110(2)을 10진수로 변환하면 4×1 + 2×1 + 1×0이므로 6(10)임을 알 수 있기 때문이죠. 여기까진 아무런 문제가 없습니다.
하지만 여기서 한 가지 문제가 생깁니다. 바로 음수는 어떻게 표현할 것인가입니다. 일상적으로는 숫자 앞에 - 기호를 붙여 음수를 표현하지만, 컴퓨터 내부에서는 이러한 방식이 비효율적입니다. 그 이유는 연산을 수행할 때마다 부호를 따로 처리해야 하기 때문입니다. 즉, 덧셈이나 뺄셈을 할 때마다 “이 값이 양수인지 음수인지”를 따로 판단해야 하므로 계산이 복잡해집니다.
그래서 컴퓨터에서는 음수를 표현하기 위해 2의 보수(Complement)라는 방식을 사용합니다. 2의 보수의 기본 아이디어는 어떤 수와 그 음수를 더했을 때 결과가 0이 되도록 만드는 것입니다. 예를 들어 6과 -6을 더하면 0이 되어야 합니다.
컴퓨터는 2진수를 기반으로 데이터를 표현하지만, 계산을 수행할 때 중요한 특징이 있습니다. 바로 오버플로우(Overflow)입니다. 오버플로우란, 정해진 비트 수로 표현할 수 있는 범위를 넘어서는 값이 발생할 때, 넘친 값이 버려지고 다시 처음으로 돌아가는 현상을 의미합니다. 예를 들어 8비트로 표현할 수 있는 최대 값을 넘어서면, 값이 순환하듯이 다시 작은 값으로 돌아가게 됩니다.

char형 변수가 있는데, char형의 모든 비트가 1로 저장되어 있다고 가정해봅시다. 즉, 값은 11111111입니다. 여기에 1을 더해보겠습니다. char형은 8비트로 정보를 표현하지만, 11111111 + 1의 연산 결과는 9비트가 되어 100000000이 됩니다. 이때 8비트를 초과하는 가장 왼쪽의 1은 버려지게 됩니다. 표현할 수 있는 범위를 초과해서 버려지는 경우를 오버플로우라고 합니다.
이 오버플로우 현상을 이용한다면 - 기호 없이도 음수를 잘 변환시켜서 6과 -6을 더했을 때 0이 되도록 할 수 있을 것 같습니다. 2의 보수는 모든 수를 뒤집은 후 1를 더한 값입니다. 아래 예시는 char형의 6을 -6으로 표현하는 과정입니다. 6으로 표현된 비트를 뒤집습니다. 여기서 뒤집는다는 것은 0을 1로, 1을 0으로 바꾼다는 것입니다. 그 후 뒤집은 값에 1을 더하면 됩니다.

참고로 뒤집기만 한 수를 1의 보수라고 합니다. 즉 위 과정에서 중간의 데이터인 11111001이 6의 1의 보수죠. 1의 보수와 더하면 모든 비트가 1이 된다는 특징이 있습니다. 즉 위의 예에서 6과 6의 보수를 더해봅시다.

모든 비트가 1이 됩니다. 이는 6이 아니라 다른 어떤 수도 마찬가지입니다. 이 모든 비트가 1이 된 상태에서 1을 더하면 오버플로우가 발생하여 0이 됩니다.
이제 감이 잡히시나요? 2의 보수는 1의 보수에 1을 더한 값입니다. 즉, 임의의 값과 그 값의 2의 보수를 더하면 오버플로우가 발생하여 0이 됩니다. 즉 2의 보수는 음수를 표현하기에 적절한 표현법이 되는 것이죠. 이러한 오버플로우의 특성을 이용하여, 컴퓨터는 별도의 부호 처리 없이도 음수를 자연스럽게 표현할 수 있으며, 이것이 바로 2의 보수 방식의 핵심 원리입니다.
모든 정수형이 음수를 2의 보수를 통해 표현합니다. 다만 unsigned 정수형은 2의 보수를 사용하지 않습니다. 왜냐면 2의 보수법 자체가 음수를 표현하기 위한 방법인데 unsigned 자료형들은 음수를 표현하지 않기 때문이죠.
| 10진수 | 2진수 |
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
unsigned 자료형들은 0부터 시작하여 1, 2, 3, ... 계속 이어서 양수만 저장합니다. 물론 unsigned 자료형도 오버플로우가 발생합니다. 이를 알아보는 코드를 실행해보도록 하겠습니다.

unsigned char형에 모든 비트가 1로 설정된 값은 10진수로 255입니다. 그러면 코드에 unsigned char 변수에 255를 저장해보도록 하겠습니다. 위 그림대로라면 255에 1을 더하면 오버플로우가 발생하여 범위를 벗어난 9번째 비트의 1이 날라가고 0만 남게 됩니다.
#include <stdio.h>
int main(void) {
unsigned char value = 255;
printf("before value : %d \n", value);
value++; // value를 1 증가시키는 코드
printf("after value : %d \n", value);
return 0;
}결과는 아래와 같습니다. 그림과 마찬가지로 모든 비트가 1인 경우에서 1을 증가시키면 unsigned char형이 저장할 수 있는 범위를 초과하게 되어 오버플로우가 발생하게 됩니다.
before value : 255
after value : 0
참고로 오버플로우는 프로그램을 컴파일하는데 오류를 발생시키진 않지만 의도에 맞지 않는 결과가 출력될 수 있으므로 주의하시길 바랍니다!
∨ 부동 소수점(실수)
∨ 퀴즈

∨ 정리
지금까지
읽어 주셔서 감사합니다!
'지식 아카이브 > C언어' 카테고리의 다른 글
| Chapter 8.5. C언어 : 비트 연산자 부연 설명. 하드웨어적 연산 비트 연산! (0) | 2026.04.19 |
|---|---|
| Chapter 8. C언어 : 연산자, 사칙 연산부터 비교 연산까지! (0) | 2026.04.19 |
| Chapter5. C언어 : 변수의 선언, 대입, 초기화, 참조. (0) | 2026.04.15 |
| Chapter4. C언어 : only 실습 모드 (0) | 2026.04.15 |
| Chapter3. C언어 : 코드에 대한 기본 구조. 주석 (0) | 2026.04.15 |